Doba čtení: 4 minut
Problém nebyl způsoben – přímo ani nepřímo – kyberútokem ani žádnou škodlivou aktivitou. Byl spuštěn změnou oprávnění v jednom z našich databázových systémů, která způsobila, že databáze začala generovat více položek do „feature file“, souboru používaného naším systémem pro správu botů. Tento soubor se následně zdvojnásobil svou velikostí. Poté byl tento neočekávaně velký soubor distribuován do všech strojů v naší síti.
Software běžící na těchto strojích, který směruje provoz napříč naší sítí, tento soubor načítá, aby udržoval systém pro správu botů aktuální vůči neustále se měnícím hrozbám. Software měl však nastavený limit velikosti souboru, který byl nižší než nově zdvojnásobená velikost. To vedlo k selhání softwaru.
Poté, co jsme nejdříve mylně předpokládali, že symptomy jsou způsobeny masivním DDoS útokem, jsme následně správně identifikovali hlavní příčinu. Zastavili jsme šíření chybného souboru a nahradili jej jeho starší, funkční verzí. Od 14:30 začal základní provoz opět proudit normálně. Následující hodiny jsme řešili zvýšenou zátěž na různých částech naší sítě, která vznikla návratem provozu. Od 17:06 již všechny systémy Cloudflare fungovaly normálně.
Omlouváme se za dopad na naše zákazníky i na celý Internet. Vzhledem k významu Cloudflare v internetovém ekosystému je jakýkoli výpadek našich systémů nepřijatelný. Skutečnost, že naše síť nebyla po určitou dobu schopná směrovat provoz, byla pro celý náš tým bolestivá. Víme, že jsme vás zklamali.
Tento text detailně popisuje, co přesně se stalo a které systémy selhaly. Je to začátek, nikoli konec, kroků, které podnikneme, aby se podobná situace už neopakovala.
Výpadek
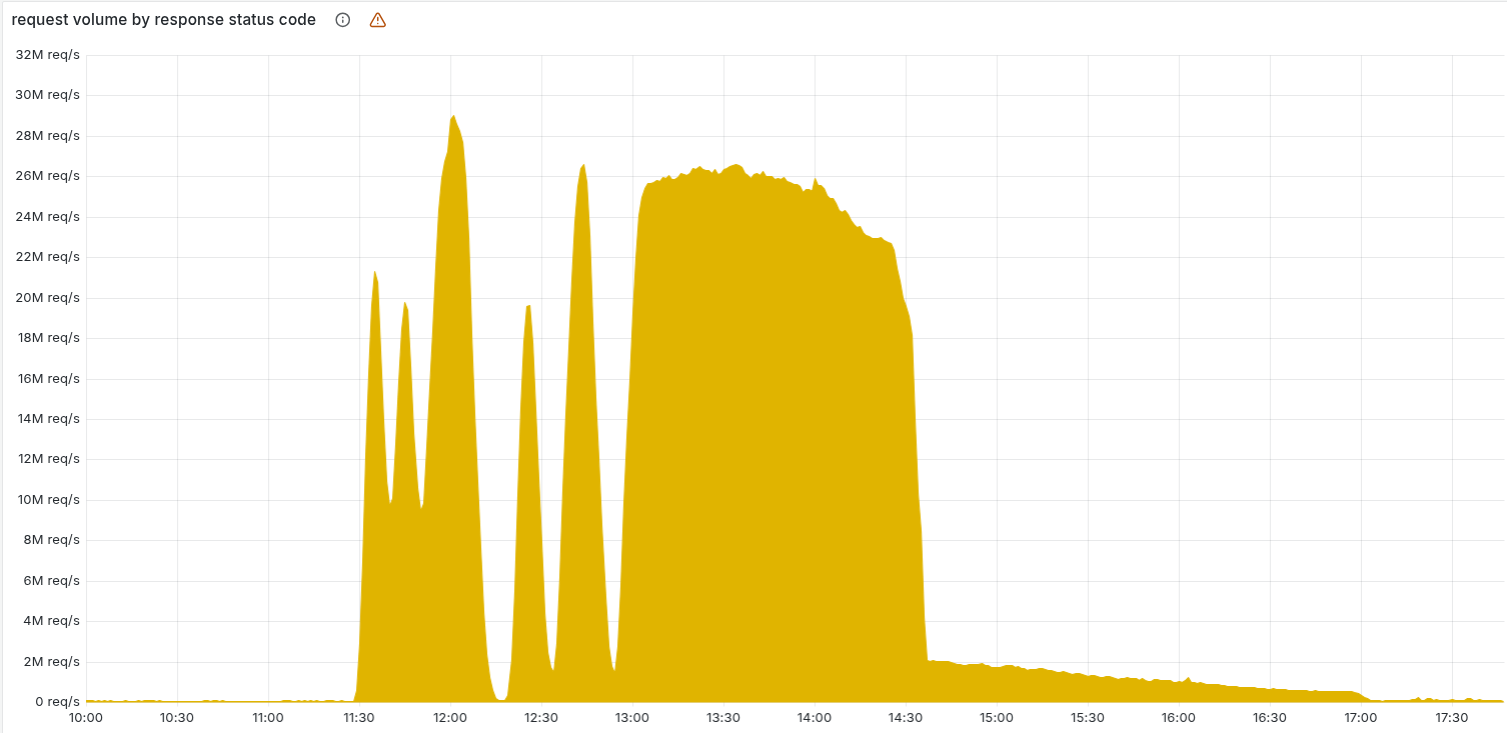
Graf níže ukazuje objem HTTP chyb 5xx generovaných sítí Cloudflare. Za normálních okolností je tento objem velmi nízký — a tak tomu i bylo až do začátku incidentu.
(… celá dlouhá pasáž o grafech, fluktuaci konfigurací, chybných dotazech do ClickHouse a střídavém generování dobrých/špatných konfiguračních souborů …)
Selhání pokračovalo, dokud jsme v 14:30 neidentifikovali a nevyřešili hlavní problém. Zastavili jsme generování a šíření špatného souboru a ručně jsme vložili funkční verzi do distribuce. Poté jsme restartovali core proxy.
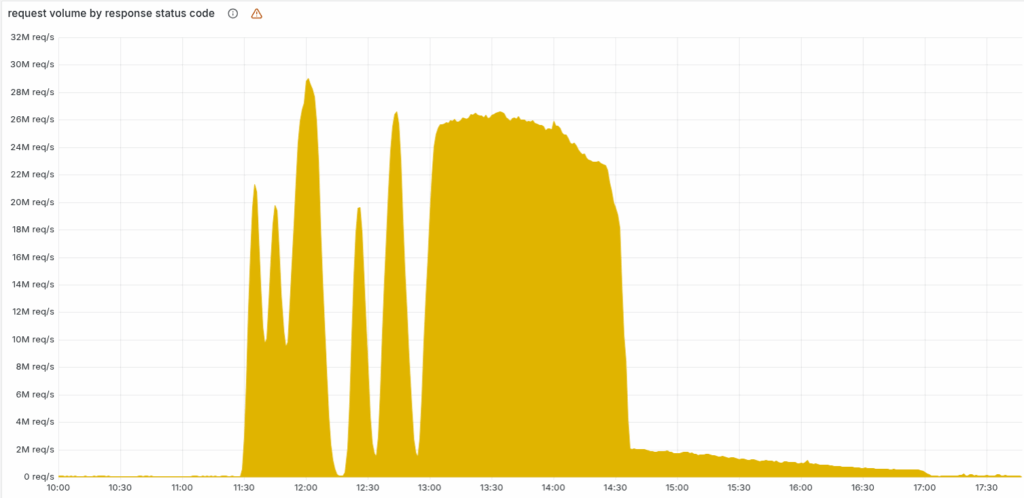
Zbytek chybových hodnot na grafu odpovídá restartům dalších služeb, které se dostaly do špatného stavu. Plná stabilita byla dosažena v 17:06.
Dotčené služby
Core CDN a bezpečnostní služby
→ HTTP chyby 5xx na straně uživatele.
Turnstile
→ Nepodařilo se načíst.
Workers KV
→ Výrazné zvýšení 5xx chyb – zkrachovalo napojení na core proxy.
Dashboard
→ Většina uživatelů se nemohla přihlásit kvůli nefunkčnímu Turnstile.
Email Security
→ Dočasná ztráta přístupu ke zdroji reputace IP → nižší přesnost detekce spamu.
→ Některé akce „Auto Move“ selhaly, vše bylo následně ručně zkontrolováno.
Access
→ Masivní selhání autentizace pro většinu uživatelů.
→ Stávající relace nebyly ovlivněny.
→ Přihlášení, která proběhla úspěšně, byla zaznamenána správně.
Jak Cloudflare zpracovává požadavky a co se rozbilo
(… celá sekce o architektuře FL/FL2, modulárním proxy systému, Bot Management modulu, feature file, strojovém učení a duplicitních řádcích …)
Kritickou závadou bylo překročení limitu počtu „features“ (200), které modul pro správu botů dokáže zpracovat. Chybný soubor měl více než 200 položek → modul způsobil panic → proxy vracela 5xx chyby.
Další dopady
Workers KV, Access, Dashboard – všechny trpěly různými typy selhání kvůli závislosti na core proxy.
Byla provedena dočasná nápravná opatření, obcházející proxy, což snížilo chybovost.
Nápravná opatření
Cloudflare uvádí, že nyní:
-
zpřísní validaci interních konfiguračních souborů,
-
zavede další globální „kill switche“,
-
vyloučí možnost zahlcení systémů core dumpy,
-
provede revizi chybových stavů ve všech proxy modulech.
Závěr
Výpadek byl nejhorší od roku 2019 a Cloudflare jej označuje za nepřijatelný.
Došlo ke kompletnímu přerušení jádrového provozu — což nemělo nastat.
Cloudflare se omlouvá a slibuje posílení infrastruktury, aby se podobný výpadek už neopakoval.

